科学計算総合研究所(Research Institute of Computational Science Co. Ltd., RICOS)では、CAEを用いた理想的な最適設計を機械学習の技術を用いて実現しようとしています。特に、有限要素法(Finite Element Method, FEM)の機械学習に注力しています。具体的な方針を以下に示します:
幾何学の機械学習で深層学習を用いたものは特にGeometric Deep Learningという言葉でまとめられているようです。Google Trendsで見てみると、近年注目度が増してきてはいるものの、まだまだポピュラーとはいえないようです1。
Geometric Deep Learningがまだあまりポピュラーになっていない原因としては、特徴量選択の難しさと学習アルゴリズムの難しさが挙げられると思います。詳しくは後述しますが、形状(とくに3次元形状)を表す方法は何通りもあり、またどれも一長一短でこれがすべてにおいてベストといったものは存在していない現状です。学習アルゴリズムはデータ構造に依存する部分も大きいため、当然学習アルゴリズムの選択も難しくなってきます。
しかしながら、物体検知やモーションキャプチャなどの領域で有用であることからコンピュータビジョンなどの領域では盛んに研究され始めている分野でもあります。この節では、Ahmed et al.のサーベイ論文2 をベースに、3 次元形状の表現方法とその機械学習の例について紹介してきます。
3次元形状の表現方法
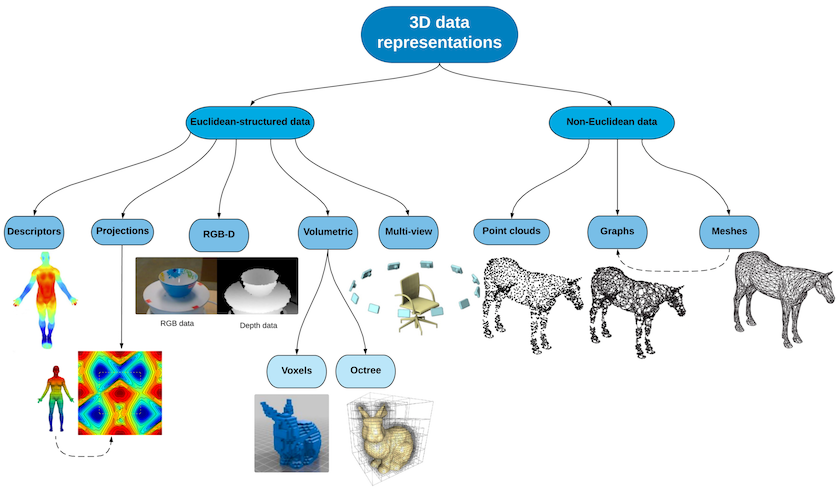
3次元形状の表現方法は、以下の図がわかりやすいと思います。この論文では大きく、Euclidean-structured data と Non-Euclidean data に分けています。ここではざっくり、画像のように格子状の構造になっているデータ(Euclidean-structured data)かそうでないデータ(Non-Euclidean data)か、くらいのイメージで十分かと思います3。以下では、それぞれの表現方法について見ていきます。
3 次元形状の表現方法の一覧
3D shape descriptor
3D shape descriptorは、3Dオブジェクトの空間から有限次元の別の空間への写像と考えられます4。例えば、形状をモーメント、オイラー標数などの位相不変量、フーリエ変換をした際のスペクトラムなどに変換し、それを特徴量とする方法です。近年では、手でこれらの特徴量を抽出して、より高次な特徴量を機械学習によって生成するといったことも行われているようです。
3D point cloudは、3次元空間上の点群(point cloud)と呼ばれる点の集まりで形状を表現したものです。これもデータ自体の長所ではないですが、3次元形状を実際に3Dスキャナなどで測定するとだいたいのデータの形式はこの3D point cloudになるのではないでしょうか。そのため、学習タスクのスタートラインがどうしてもこの形式にならざるを得ないことが多く、3D point cloudをいかにうまく扱うかは応用上非常に重要であると考えられます。また、点の集まりとはいえ3次元の情報を持っているため、3次元形状の概形をつかむのには適していると言えます。
3D point cloudの例
主な短所は3つ挙げられます。一つめは、3D point cloudは実際の形状を測定したものであることが多く、ノイズが乗っていることが多いことです。二つめは、点どうしがどのように繋がっているかの情報が欠けていることにより、どこが表面であるかの情報が不確かになってしまっていることです。三つめは、複数の形状を独立に測定したとすると、点群の個数は異なりますし、それらの順番が不同であることです。機械学習モデルでは入出力を多次元配列で与えることが多いと思いますが、配列のサイズが不定であり、また順番を一意に決められないということになり、学習タスクをうまく回す上で重大な障害になります。
この中で Deep Setsについて少し触れておきます。この論文の主なコントリビューションは、配列の順序を入れ替えても計算結果が変わらない(=順不同データを扱える)関数を記述し、それが必要十分であることを数学的に証明したことです。これによって、順不同のデータを扱う機械学習モデルを作る際の強力な指針が得られたことになります。
E. Ahmed, A. Saint, A. E. R. Shabayek, K. Cherenkova, R. Das, G. Gusev, D. Aouada and B. Ottersten, “Deep Learning Advances on Different 3D Data Representations: A Survey,” arXiv preprint arXiv:1808.01462, 2018. ↑
L. Zhang, M. J. da Fonseca, A. Ferreira, and C. R. A. eRecuperac ̧a ̃o,“Surveyon3dshapedescriptors,”FundaA ̃gaopara a Cincia ea Tecnologia, Lisboa, Portugal, Tech. Rep. Technical Report, DecorAR (FCT POSC/EIA/59938/2004), vol. 3, 2007. ↑
O. Vinyals, S. Bengio, and M. Kudlur, “Order matters: Sequence to sequence for sets,” arXiv preprint arXiv:1511.06391, 2015. ↑
S. Ravanbakhsh, J. Schneider, and B. Poczos, “Deep learning with sets and point clouds,” arXiv preprint arXiv:1611.04500, 2016. ↑
M. Zaheer, S. Kottur, S. Ravanbakhsh, B. Poczos, R. R. Salakhut- dinov, and A. J. Smola, “Deep sets,” in Advances in Neural Information Processing Systems, 2017, pp. 3394–3404. ↑
M.Fey,J.E.Lenssen,F.Weichert,andH.Mu ̈ller,“Splinecnn:Fast geometric deep learning with continuous b-spline kernels,” arXiv preprint arXiv:1711.08920, 2017. ↑
F. Monti, D. Boscaini, J. Masci, E. Rodola, J. Svoboda, and M. M. Bronstein, “Geometric deep learning on graphs and manifolds using mixture model cnns,” in Proc. CVPR, vol. 1, no. 2, 2017, p. 3. ↑
By clicking the "I agree" button, you consent to the use of cookies, which will allow you to use all of the features of our website. If you would like more information about cookies or would like to change your cookie settings, please see our Cookie Policy.